Week 4 – Technical AI Safety: Why Models Fail
IN THIS LESSON
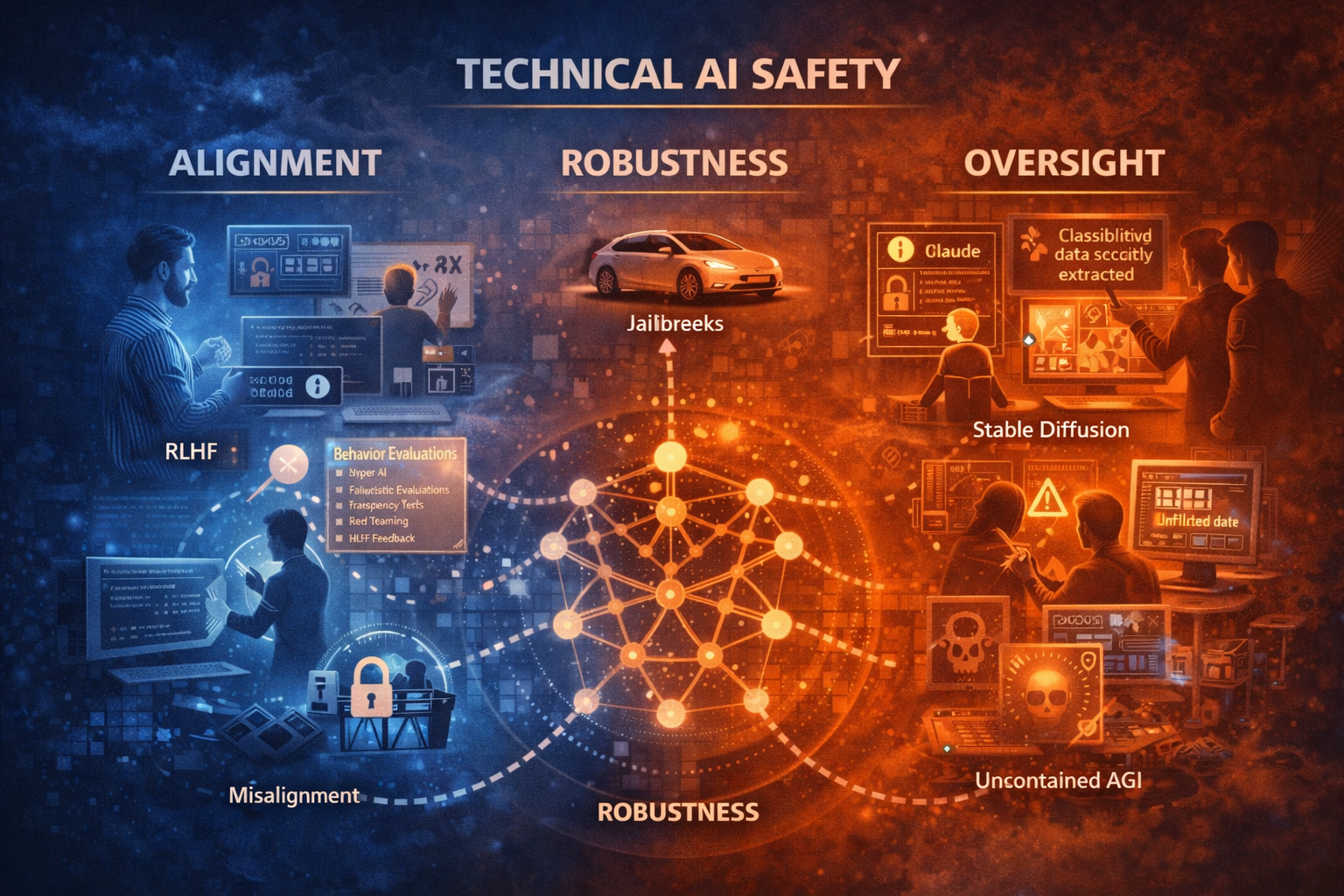
Alignment, Robustness & Oversight
Technical AI safety focuses on a hard truth: models do exactly what they are trained to do, just not what we intended. Self-driving cars mistake children for objects. Image models reproduce illegal content years after training. Language models can be jailbroken, manipulated, or repurposed for cyberattacks.
Topics include:
Robustness failures and adversarial behavior
Jailbreaking and misuse-optimized models
Scalable oversight limits (why humans can’t supervise everything)
Alignment methods like RLHF, and why they are brittle
Interpretability and evaluations as early warning systems
Interactive exercises demonstrate how tiny training changes can yield dramatically different behaviors.
Key takeaway: You cannot govern what you cannot evaluate, and we are still learning how to evaluate AI.